一、概述
Redis 是一种基于键值对(key-value)的高性能内存数据库。与很多键值对数据库不同的是,Redis 的值支持 string(字符串)、 hash(哈希)、list(列表)、set(集合)、 zset(有序集合)、Bitmaps(位图)、HyperLogLog、GEO(地理信息定位) 等多种数据结构,因此适用场景也更加丰富。Redis 是用 C 语言实现的,采用单线程架构,把所有的数据都放到内存中,因此 Redis 速度很快。除此之外,Redis 还提供了 持久化、主从复制、集群 以及以下几点功能:
- 提供了键过期功能,可以用来实现缓存。
- 提供了发布订阅功能,可以用来实现消息系统。
- 支持 Lua 脚本功能,可以根据需要定制自己的 Redis 命令。
- 提供了简单的事务功能, 能在一定程度上保证事物特性。
- 提供了流水线(Pipeline)功能, 客户端可以将一批命令一次性传到 Redis,从而减少网络的开销。
Redis 内部使用一个 redisObject 对象来表示所有的 key 和 value。redisObject 最主要的信息如图所示:
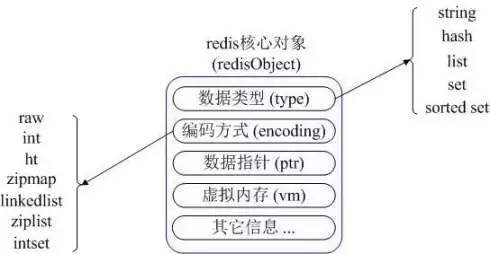
其中 type 代表一个 value 对象具体是何种数据类型,encoding 是不同数据类型在redis内部的存储方式,比如:type=string 代表 value 存储的是一个普通字符串,那么对应的 encoding 可以是 raw 或者是 int。
二、Redis提供的五种数据结构
五种数据结构:
| 数据类型 | 可以存储的值 | 操作 |
|---|---|---|
| STRING | 字符串、整数或者浮点数 | 对整个字符串或者字符串的其中一部分执行操作 对整数和浮点数执行自增或者自减操作 |
| LIST | 列表 | 从两端压入或者弹出元素 读取单个或者多个元素 进行修剪,只保留一个范围内的元素 |
| SET | 无序集合 | 添加、获取、移除单个元素 检查一个元素是否存在于集合中 计算交集、并集、差集 从集合里面随机获取元素 |
| HASH | 包含键值对的无序散列表 | 添加、获取、移除单个键值对 获取所有键值对 检查某个键是否存在 |
| ZSET | 有序集合 | 添加、获取、删除元素 根据分值范围或者成员来获取元素 计算一个键的排名 |
STRING
字符串类型是 Redis 最基础的数结构。首先键都是字符串类型, 而且其他几种数据结构 都是 在字符串类型基础上构建的。

上图是string 在 redis 中的宏观样子,它的数据结构如下图所示:
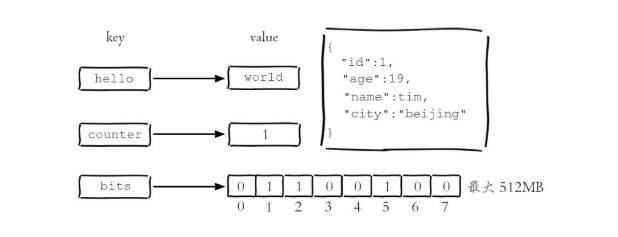
常用命令
每种数据类型对应的命令都非常多,以下只列举 string 比较常用的命令,方便日后查看:
| 命令 | 用法 | 描述 |
|---|---|---|
| set | set key value | 设置指定 key 的值 |
| get | get key | 获取指定 key 的值 |
| del | del key | 删除指定 key 的值 |
| setex | setex key seconds value | 设置健并指定多少秒后过期 |
| setnx | setnx key value | 只有当 key 不存在时才设置成功(setnx 可以作为分布式锁 的一种实现方案) |
| mset | mset key1 value1 key2 value2 … | 批量设置多个 key-value 对 |
| mget | mget key1 key2 key3 … | 批量获取多个 key 的值 |
| incr | incr key | 对值做自增操作 |
mset、mget 等批量操作可以减少网络传输的次数,从而可以提高效率。
下面简单使用下一些命令:
1 | > set hello world |
string 的典型使用场景:
- 缓存功能
- 计数
- 共享 Session
- 限速
HASH
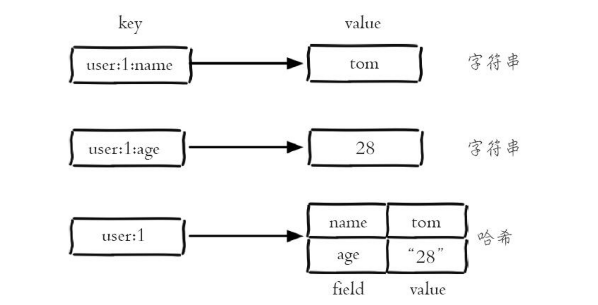
哈希类型是指键值本身又是一个键值对结构,形如:
1 | value={{ field1, value1},...{ fieldN, valueN}} |
如下图所示:

下图是字符串和哈希类型的对比:
常用命令
以下只列举 hash 比较常用的命令,方便日后查看:
| 命令 | 用法 | 描述 |
|---|---|---|
| hset | hset key field value | 将哈希表 key 中的字段 field 的值设为 value |
| hget | hget key field | 获取存储在哈希表中指定字段的值 |
| hdel | hdel key field1 field2 … | 删除一个或者多个 field |
| hlen | hlen key | 计算 field 个数 |
| hmset | hmset key field value field1 field2 … | 批量设置一个key中的多个字段 |
| hmget | hmget key field field1 field2 … | 批量获取一个key中的多个字段 |
| hexists | hexists key field | 判断 key 中是否存在某个 field |
| hkeys | hkeys key | 获取指定 key 中的所有 field |
| hvals | hvals key | 获取指定 key 中的所有 value |
| hgetall | hgetall key | 获取指定 key 中的所有 field-value |
在使用 hgetall 时, 如果哈希元素个数比较多,会存在阻塞 Redis 的可能。如果只需要获取部分 field,可以使用 hmget,如果一定要获取全部 field-value,可以使用 hscan 命令,该命令会渐进式遍历哈希类型。
下面简单使用下一些命令:
1 | > hset hash-key sub-key1 value1 |
hash 的典型使用场景:
比如缓存用户信息。每个用户属性使用一对field-value,但是只用一个键保存。如下图所示:
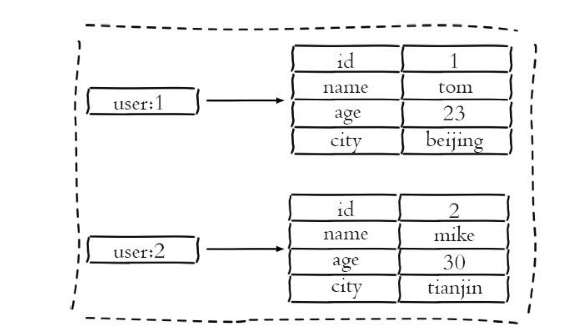
优点:简单直观,如果使用合理可以减少内存空间的使用。
缺点:要控制哈希在ziplist和hashtable两种内部编码的转换,hashtable会消耗更多内存。
LIST
列表类型是用来存储多个有序的字符串,支持两端插入(push)和弹出(pop),还可以获取指定范围的元素列表、获取指定索引下标的元素等。列表是一种比较灵活的数据结构,它可以充当栈和队列的角色,在实际开发上有很多应用场景。

下图为列表两端插入和弹出操作,a、b、c、d、e五个元素从左到右组成了一个有序的列表,列表中的每个字符串称为元素(element),一个列表最多可以存储232-1个元素。
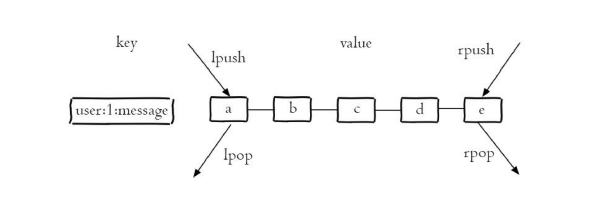
常用命令
以下只列举 list 比较常用的命令,方便日后查看:
| 命令 | 用法 | 描述 |
|---|---|---|
| rpush | rpush key value1 value2 … | 从右边插入一个或多个元素 |
| lpush | lpush key value1 value2 … | 从左边插入一个或多个元素 |
| linsert | linsert key before | 在 pivot 前或者后插入一个新元素 value |
| lrange | lrange key start end | 获取指定索引范围内的所有元素,索引下标从左到右分别是0到N-1,但是从右到左分别是-1到-N。 lrange key 0 -1 表示从左到右获取列表的所有元素 |
| lindex | lindex key index | 获取列表指定索引下标的元素,lindex key -1 表示获取列表的最后一个元素 |
| llen | llen key | 获取列表长度 |
| lpop | lpop key | 从列表左侧弹窗元素 |
| rpop | rpop key | 从列表右侧弹出元素 |
| lrem | lrem key count value | 当 count>0 , 从左到右,删除count个值等于 value的元素;当 count<0,从右到左,删除count的绝对值个值等于value的元素;当 count=0,删除所有值等于 value的元素 |
| ltrim | ltrim key start end | 只保留key 从start 到end 的元素 |
| lset | lset key index newValue | 修改指定索引小标的元素 |
下面简单使用下一些命令:
1 | > rpush list-key item |
list 的典型使用场景:
- 消息队列
- 文章列表
实际上列表的使用场景很多,在选择时可以参考以下口诀:
1 | ·lpush+lpop=Stack(栈) |
SET
集合类型也是用来保存多个的字符串元素,但和列表类型不同的是,集合中的元素是无序并且不可重复的,不能通过索引下标获取元素。Redis除了支持集合内的增删改查,同时还支持多个集合取交集、并集、差集,合理地使用好集合类型,能在实际开发中解决很多实际问题。

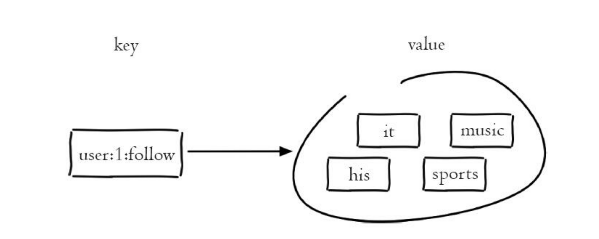
常用命令
以下只列举 set 比较常用的命令,方便日后查看:
| 命令 | 用法 | 描述 |
|---|---|---|
| sadd | sadd key value1 value2 … | 添加一个或多个元素 |
| srem | srem key value1 value2 … | 删除一个或多个元素 |
| scard | scard key | 计算元素个数 |
| sismember | sismember key element | 判断元素是否在集合中,返回1表示存在,0 表示不存在 |
| srandmember | srandmember key count | 随机从集合返回count个元素,count 不写默认为1 |
| spop | spop key | 从集合随机弹出元素 |
| smembers | smembers key | 获取所有元素 |
| sinter | sinter key1 key2 … | 求多个集合的交集 |
| suinon | suinon key1 key2 … | 求多个集合的并集 |
| sdiff | sdiff key1 key2 … | 求多个集合的差集 |
| sinterstore | sinterstore key key1 key2 … | 求多个集合的交集并保存到key中 |
| suinonstore | suinonstore key key1 key2 … | 求多个集合的并集并保存到key中 |
| sdiffstore | sdiffstore key key1 key2 … | 求多个集合的差集并保存到key中 |
smembers和lrange、hgetall都属于比较重的命令,如果元素过多存在阻塞Redis的可能性,这时候可以使用sscan来完成。
下面简单使用下一些命令:
1 | > sadd set-key item |
set 的典型使用场景:
- sadd=Tagging(标签)
- spop/srandmember=Randomitem(生成随机数,比如抽奖)
- sadd+sinter=SocialGraph(社交需求)
标签(tag)是集合类型一个比较典型的使用场景。例如一个用户可能对娱乐、体育比较感兴趣,另一个用户可能对历史、新闻比较感兴趣,这些兴趣点就是标签。有了这些数据就可以得到喜欢同一个标签的人,以及用户的共同喜好的标签。
ZSET(sorted set)
有序集合,保留了集合元素不可重复的特性,并在集合的基础上增加了元素排序功能。需要注意的是,它和列表使用索引下标作为排序依据不同的是,它给每个元素设置一个分数(score)作为排序的依据。有序集合还提供了获取指定分数和元素范围查询、计算成员排名等功能,合理的利用有序集合,能帮助我们在实际开发中解决很多问题。

下图是一个有序集合的例子,该有序集合包含kris、mike、frank、tim、martin、tom,它们的分数分别是1、91、200、220、250、251。
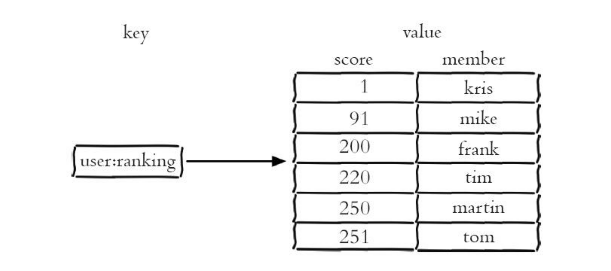
常用命令
以下只列举 zset 比较常用的命令,方便日后查看:
| 命令 | 用法 | 描述 |
|---|---|---|
| zadd | zadd key score member [score member …] | 向有序集合添加一个或多个成员以及分数,或者更新已存在成员的分数 |
| zcard | zcard key | 计算成员个数 |
| zscore | zscore key member | 计算某个成员的分数,存在则返回分数,否则返回 nil |
| zrank | zrank key element | 返回分数从低到高的排名 |
| zrevrank | zrevrank key count | 返回分数从高到低的排名 |
| zrem | zrem member [member …] | 删除一个或多个成员 |
| zincrby | zincrby key increment member | 给key中的member 增加 increment 分 |
| zrange | sinter key1 key2 … | 求多个集合的交集 |
| zremrangebyscore | zremrangebyscore key min max | 删除指定分数范围的成员 |
zset 同样可以计算集合的交、并、差,以上没有一一列举
下面简单使用下一些命令:
1 | > zadd zset-key 728 member1 |
zset 的典型使用场景:
有序集合比较典型的使用场景就是排行榜系统。例如视频网站需要对用户上传的视频做排行榜,榜单的维度可能是多个方面的:按照时间、按照播放数量、按照获得的赞数。
以点赞数位例,主要需要实现以下4个功能
- 添加用户赞数
- 取消用户赞数
- 展示获取赞数最多的十个用户
- 展示用户信息以及用户分数
三、Redis的使用场景
由于 redis 支持多种数据类型,所以适用场景也非常多。
缓存
对于热点数据,缓存的价值非常大。例如,分类栏目(读频率高)等。可以将这些热点数据放到内存中,通过设置内存的最大使用量以及淘汰策略来保证缓存的命中率。
共享Session(会话缓存)
在分布式场景下具有多个应用服务器,可以使用 Redis 来统一存储这些应用服务器的会话信息。比如我们公司就使用Redis共享Session来实现单点登录。
计数器
数据统计的需求非常普遍,通过原子递增保持计数。例如,应用数、资源数、点赞数、收藏数、分享数等。这种高频率读写的特征可以完全发挥 Redis 作为内存数据库的高效。在 Redis 的数据结构中,string、hash和sorted set都提供了incr方法用于原子性的自增操作。
排行榜以及热门列表
例如视频网站需要对用户上传的视频做排行榜,榜单的维度可能是多个方面的:比如按照时间、播放量、点击率、点赞数等。可以利用有序集合 zset 实现。
社交列表
社交属性相关的列表信息,例如,用户点赞列表、用户分享列表、用户收藏列表、用户关注列表、用户粉丝列表等,使用 Hash 类型数据结构是个不错的选择。
记录用户判定信息
记录一个用户是否进行了某个操作。例如,用户是否点赞、用户是否收藏、用户是否评论分享等。
交集、并集和差集
在某些场景中,例如社交场景,通过交集、并集和差集运算,可以非常方便地实现共同好友,共同关注,共同偏好等社交关系。
时效性
例如验证码只有60秒有效期,超过时间无法使用,或者基于 Oauth2 的 Token 只能在 5 分钟内使用一次,超过时间也无法使用。
消息队列
Redis 中list的数据结构实现是双向链表,所以非常适合应用于消息队列(生产者/消费者模型)。 生产者利用 lpush 命令将数据添加到链表头部,消费者通过 brpop(右端阻塞弹出) 命令将元素从链表尾部取出。并且可以保证消息的有序性。比如可以用这种方式让多个应用更新最新的内容。
不过最好还是用 RabbitMQ 等市面上成熟的消息队列中间件。
分布式锁实现
由于Redis的单线程命令处理机制,如果有多个客户端同时执行 setnx key value,根据setnx的特性只有一个客户端能设置成功,setnx可以作为分布式锁的一种实现方案。除此之外,还可以使用官方提供的 RedLock 分布式锁实现。
四、Redis的数据淘汰策略(内存淘汰机制)
内存淘汰的过程
首先,客户端发起了需要申请更多内存的命令(如set)。
然后,Redis检查内存使用情况,如果已使用的内存大于 maxmemory 则开始根据用户配置的不同淘汰策略来淘汰内存(key),从而换取一定的内存。
最后,如果上面都没问题,则这个命令执行成功。
8 种淘汰策略
当Redis所用内存达到maxmemory上限时会触发相应的溢出控制策略。具体策略受maxmemory-policy参数控制,Redis支持以下6种策略:
| 策略 | 描述 |
|---|---|
| noeviction | 当内存达到限制的时候,不淘汰任何数据,不可写入任何数据集,所有引起申请内存的命令会报错 |
| volatile-ttl | 从已设置过期时间的数据集中挑选将要过期的数据淘汰 |
| allkeys-lru | 从所有数据集中挑选最近最少使用的数据淘汰 |
| volatile-lru | 从已设置过期时间的数据集中挑选最近最少使用的数据淘汰 |
| allkeys-random | 从所有数据集中任意选择数据进行淘汰 |
| volatile-random | 从已设置过期时间的数据集中任意选择数据淘汰 |
| allkeys-lfu | 从所有键中驱逐使用频率最少的键 |
| volatile-lfu | 从已设置过期时间的数据集中挑选使用频率最少的键 |
需要注意的是:作为内存数据库,出于对性能和内存消耗的考虑,Redis 的淘汰算法实际实现上并非针对所有 key,而是抽样一小部分并且从中选出被淘汰的 key。
如何选择淘汰策略
下面看看几种策略的适用场景
allkeys-lru:如果我们的应用对缓存的访问符合幂律分布,也就是存在相对热点数据,或者我们不太清楚我们应用的缓存访问分布状况,我们可以选择allkeys-lru策略。
allkeys-random:如果我们的应用对于缓存key的访问概率相等,则可以使用这个策略。
volatile-ttl:这种策略使得我们可以向Redis提示哪些key更适合被eviction。
推荐用法:
使用 Redis 缓存数据时,为了提高缓存命中率,需要保证缓存数据都是热点数据。可以将内存最大使用量设置为热点数据占用的内存量,然后启用 allkeys-lru 淘汰策略,将最近最少使用的数据淘汰。
Redis 4.0 引入了 volatile-lfu 和 allkeys-lfu 淘汰策略,LFU 策略通过统计访问频率,将访问频率最少的键值对淘汰。
如何配置最大内存及淘汰策略
我们通过配置redis.conf中的 maxmemory 这个值来开启内存淘汰功能,以及配置淘汰策略
1 | # 设置最大内存 |
需要注意的是,maxmemory 为0的时候表示我们对Redis的内存使用没有限制。
此外,redis支持动态改配置,无需重启。
设置最大内存
1 | config set maxmemory 100000 |
设置淘汰策略
1 | config set maxmemory-policy noeviction |
五、Redis 的持久化机制
Redis支持RDB和AOF两种持久化机制,通过持久化机制把内存中的数据同步到硬盘文件来保证数据持久化,从而能有效地避免因进程退出造成的数据丢失问题,当下次重启时利用之前持久化的文件即可实现数据恢复。
RDB 快照持久化
RDB是Redis默认的持久化方式。按照一定的时间周期策略把内存的数据生成快照(Snapshot)以紧凑压缩的二级制文件格式保存到硬盘。
触发RDB持久化过程分为手动触发和自动触发。手动触发分别对应save和bgsave命令,其中save存在阻塞问题,基本已经废弃,Redis内部所有的涉及RDB的操作都采用bgsave的方式。执行save 或 bgsave 将在 redis 安装目录中创建dump.rdb (可配置)文件,如果需要恢复数据,只需将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可。
可以在redis.conf中做一些 RDB 相关的配置:
1 | # 快照的文件名 |
RDB的优点:
RDB是一个紧凑压缩的二进制文件,代表Redis在某个时间点上的数据快照。非常适用于备份,全量复制等场景。比如每6小时执行bgsave备份,并把RDB文件拷贝到远程机器或者文件系统中(如hdfs),用于灾难恢复。
Redis加载RDB恢复数据远远快于AOF的方式。
RDB的缺点:
RDB方式数据没办法做到实时持久化/秒级持久化。因为bgsave每次运行都要执行fork操作创建子进程,属于重量级操作,频繁执行成本过高。
一旦数据库出现问题,那么我们的RDB文件中保存的数据并不是全新的,从上次RDB文件生成到Redis停机这段时间的数据全部丢掉了。例如,每隔30分钟或者更长的时间来创建一次快照,Redis停止工作时(例如意外断电)就可能丢失这30分钟的数据。
RDB文件使用特定二进制格式保存,Redis版本演进过程中有多个格式的RDB版本,存在老版本Redis服务无法兼容新版RDB格式的问题。针对RDB不适合实时持久化的问题,Redis提供了AOF持久化方式来解决。
AOF 日志持久化
针对RDB不适合实时持久化的问题,Redis提供了AOF持久化方式来解决。开启AOF功能需要设置配置:appendonly yes,默认不开启。AOF文件名通过 appendfilename 配置设置,默认文件名是 appendonly.aof。保存路径同 RDB 持久化方式一致,通过dir配置指定。AOF的工作流程操作:命令写入(append)、文件同步(sync)、文件重写(rewrite)、重启加载(load)。如下图所示:
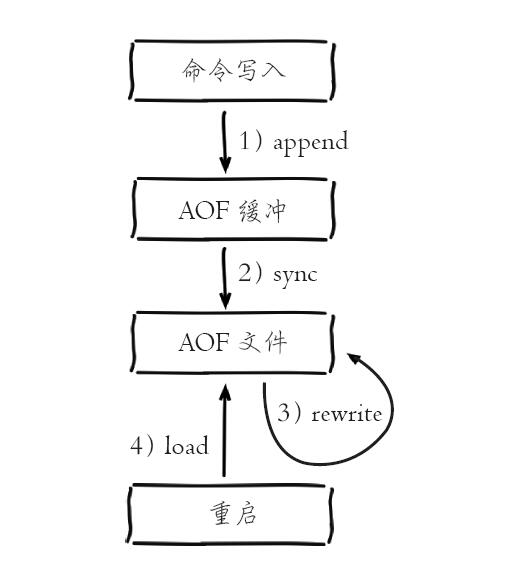
AOF 工作流程 :
1)所有的写入命令会追加到aof_buf(缓冲区)中。
2)AOF缓冲区根据对应的策略向硬盘做同步操作。
3)随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩的目的。
4)当Redis服务器重启时,可以加载AOF文件进行数据恢复。
下面分别讲下每个过程:
命令写入
AOF命令写入是吧文本协议格式的内容追加到缓存区。
如以下 set hello world 命令的文本协议格式如下:
1 | *3\r\n$3\r\nset\r\n$5\r\nhello\r\n$5\r\nworld\r\n |
采用文本协议格式的原因:
文本协议具有可读性,方便直接修改和处理。同时还可以避免二次开销。
先写入缓存区而不是直接写入硬盘的原因:
如果每次写AOF文件命令都直接追加到硬盘,那么性能完全取决于当前硬盘负载。先写入缓冲区aof_buf中,还有另一个好处,Redis可以提供多种缓冲区同步硬盘的策略,在性能和安全性方面做出平衡。
文件同步
Redis提供了多种AOF缓冲区同步文件策略,由参数appendfsync控制。Redis支持三种不同的缓冲区同步文件策略如下:
1 | #每次收到写命令就立即强制写入磁盘,是最有保证的完全的持久化,但速度也是最慢的,影响 Redis 的高性能,一般不推荐使用。 |
重写机制
随着命令不断写入AOF,文件会越来越大,为了解决这个问题,Redis引入AOF重写机制压缩文件体积。AOF文件重写是把Redis进程内的数据转化为写命令同步到新AOF文件的过程。AOF重写降低了文件占用空间,除此之外,另一个目的是:更小的AOF文件可以更快地被Redis加载。
重写的过程主要做了一下事情:
1)进程内已经超时的数据不再写入文件。
2)旧的AOF文件中的无效命令不再写入,如delkey1、hdelkey2、sremkeys、seta111、seta222 等。重写使用进程内数据直接生成,这样新的AOF文件只保留最终数据的写入命令。
3)多条写命令可以合并为一个,如:lpushlista、lpushlistb、lpushlistc可以转化为:lpushlistabc。
具体的重写流程如下图所示:
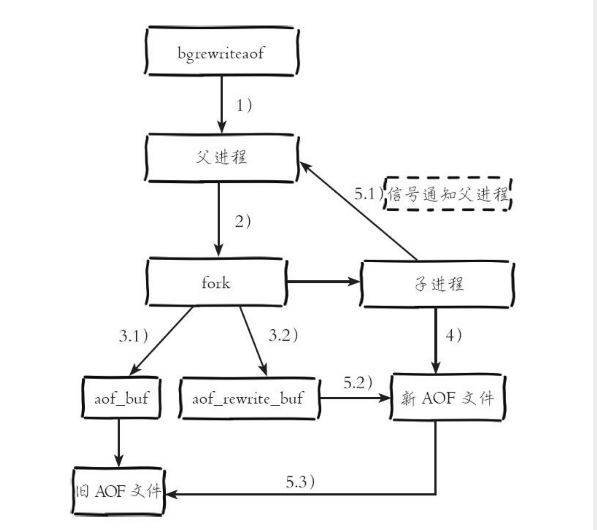
可以通过下面配置设置什么时候开启自动重写:
AOF重写过程可以手动触发(直接调用bgrewriteaof命令)和自动触发:根据配置的auto-aof-rewrite-min-size和auto-aof-rewrite-percentage参数确定自动触发时机。如下所示:
1 | # AOF文件名 |
重启加载(数据恢复)
RDB 和 AOF 文件都可以用于服务器重启时的数据恢复。
下图为 Redis 持久化文件加载流程(即重启阶段恢复数据的流程):
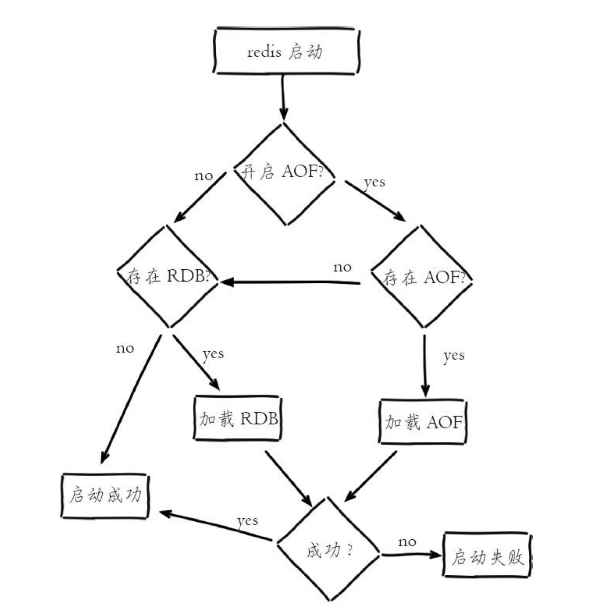
流程说明:
1)AOF持久化开启且存在AOF文件时,优先加载AOF文件。
2)AOF关闭或者AOF文件不存在时,加载RDB文件。
3)加载AOF/RDB文件成功 后,Redis 启动成功。
4)AOF/RDB文件存在错误时,Redis 启动失败并打印错误信息。
六、Redis 为什么速度快
Redis使用了单线程架构和I/O多路复用模型来实现高性能的内存数据库服务。
纯内存访问,Redis将所有数据放在内存中,内存的响应时长大约为100纳秒。
Redis采用了单线程设计,单线程避免了线程切换和竞态产生消耗。
Redis采用了非阻塞I/O模型,Redis使用epoll作为I/O多路复用技术的实现,再加上Redis自身的事件处理模型将epoll中的连接、读写、关闭都转换为事件,不在网络I/O上浪费过多的时间。
Redis是用C语言实现的,一般来说C语言实现的程序“距离”操作系统更近,执行速度相对会更快。
七、Redis 为什么采用单线程
Redis 为什么采用单线程设计,主要原因如下:
- Redis的性能瓶颈不在于CPU资源,而在于内存访问和网络IO。
- 采用单线程设计,可以极大简化数据结构和算法的实现,使代码更清晰,处理逻辑更简单。
- 单线程避免了不必要的线程切换和竞态产生消耗。
- 不用去考虑各种锁的问题,不存在加锁释放锁操作,不会出现死锁而导致的性能消耗。
采用单线程设计也有一个弊端,就是无法发挥多核CPU性能,如果某个命令执行过长,会造成其他命令的阻塞。
解决的办法是,通过在一个多核的机器上部署多个redis实例,组成master-master,master-slave的形式,实现读写分离。把耗时的读命令完全可以放到slave中来解决。
八、Redis的内部结构
Redis本质上是一个数据结构服务器(data structures server),以高效的方式实现了多种现成的数据结构,研究它的数据结构和基于其上的算法,对于我们自己提升局部算法的编程水平有很重要的参考意义。
可以通过阅读 Redis 设计与实现 来学习。
还可以参考下 Redis内部数据结构详解 系列博客
九、Redis 集群方案与实现
后面会单独写篇文章讲 Redis 的 复制、哨兵、集群。
十、Redis 与 Memcached 的差异
Redis 和 Memcache 都是基于内存的数据存储系统。Redis是一个开源的key-value存储系统,而Memcached是高性能分布式内存缓存服务。那么Redis 与 Memcached 之间有什么区别呢?
Redis的作者Salvatore Sanfilippo曾经对这两种基于内存的数据存储系统进行过比较:
Redis支持服务器端的数据操作:Redis相比Memcached来说,拥有更多的数据结构和并支持更丰富的数据操作,通常在Memcached里,你需要将数据拿到客户端来进行类似的修改再set回去。这大大增加了网络IO的次数和数据体积。在Redis中,这些复杂的操作通常和一般的GET/SET一样高效。所以,如果需要缓存能够支持更复杂的结构和操作,那么Redis会是不错的选择。
内存使用效率对比:使用简单的key-value存储的话,Memcached的内存利用率更高,而如果Redis采用hash结构来做key-value存储,由于其组合式的压缩,其内存利用率会高于Memcached。
性能对比:由于Redis只使用单核,而Memcached可以使用多核,所以平均每一个核上Redis在存储小数据时比Memcached性能更高。而在100k以上的数据中,Memcached性能要高于Redis,虽然Redis最近也在存储大数据的性能上进行优化,但是比起Memcached,还是稍有逊色。
数据类型支持不同
Redis支持的数据类型要丰富得多。最为常用的数据类型主要由五种:String、Hash、List、Set和Sorted Set。
Memcached仅支持简单的key-value结构的数据记录。
内存管理机制不同
在 Redis 中,并不是所有数据都一直存储在内存中,可以将一些很久没用的 value 交换到磁盘,而 Memcached 的数据则会一直在内存中。
Redis的内存管理主要通过源码中zmalloc.h和zmalloc.c两个文件来实现的。Redis为了方便内存的管理,在分配一块内存之后,会将这块内存的大小存入内存块的头部。
Memcached默认使用Slab Allocation机制管理内存,其主要思想是按照预先规定的大小,将分配的内存分割成特定长度的块以存储相应长度的key-value数据记录,以完全解决内存碎片问题,但是它最大的缺点就是会导致空间浪费,因为每个Chunk都分配了特定长度的内存空间,所以变长数据无法充分利用这些空间。例如块的大小为 128 bytes,只存储 100 bytes 的数据,那么剩下的 28 bytes 就浪费掉了。
数据持久化支持
Redis支持内存数据的持久化,而且提供了RDB快照和AOF日志两种主要的持久化策略。
memcached是不支持数据持久化操作的。
集群管理的不同
Redis 本身提供了 Cluster,引入Master节点和Slave节点,支持在服务器端构建分布式存储。在Redis Cluster中,每个Master节点都会有对应的两个用于冗余的Slave节点。这样在整个集群中,任意两个节点的宕机都不会导致数据的不可用。当Master节点退出后,集群会自动选择一个Slave节点成为新的Master节点。
Memcached本身并不支持分布式,因此只能在客户端通过像一致性哈希这样的分布式算法来实现Memcached的分布式存储。当客户端向Memcached集群发送数据之前,首先会通过内置的分布式算法计算出该条数据的目标节点,然后数据会直接发送到该节点上存储。但客户端查询数据时,同样要计算出查询数据所在的节点,然后直接向该节点发送查询请求以获取数据。
十一、参考文献
[1]《Redis 开发与运维》付磊; 张益军著
[2] 《Redis IN ACTION》 ah L. Carlson
[3] Redis实战 文集
[4] Redis应用场景
[5] Redis 命令参考
[6] 论述Redis和Memcached的差异
[7] MongoDB 或者 redis 可以替代 memcached 吗?