为什么要使用线程池
池化技术相比大家已经屡见不鲜了,线程池、数据库连接池、Http 连接池等等都是对这个思想的应用。池化技术的思想主要是为了减少每次获取资源的消耗,提高对资源的利用率。
这里借用《Java 并发编程的艺术》提到的来说一下使用线程池的好处:
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
如何创建线程池
方式一:通过 Executor 框架的工具类 Executors 来实现:
主要是通过下面个方法:
newFixedThreadPool : 该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
SingleThreadExecutor: 方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
newCachedThreadPool: 该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
newScheduledThreadPool:调度型线程池,支持定时及周期性任务执行,也是一个固定长度的线程池。
方式二:直接通过 ThreadPoolExecutor 来实现 (推荐使用这种)

《阿里 Java 开发手册》中关于线程以及线程池的使用有两个强制建议:
- 线程资源必须通过线程池提供,不允许在应用中自行显式创建线程。
- 线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。

我们在项目中最好还是直接ThreadPoolExecutor,并且 Executors 也是在ThreadPoolExecutor 的基础上做了一层封装,所以很有必要学习下 ThreadPoolExecutor 的工作原理以及几个重要的参数设置。
ThreadPoolExecutor构造方法及几个重要参数
一共有四个构造方法:
1 | // 五个参数的构造函数 |
涉及到5~7个参数,我们先看看必须的5个参数是什么意思:
int corePoolSize:该线程池中核心线程数最大值
核心线程:线程池中有两类线程,核心线程和非核心线程。核心线程默认情况下会一直存在于线程池中,即使这个核心线程什么都不干(铁饭碗),而非核心线程如果长时间的闲置,就会被销毁(临时工)。
int maximumPoolSize:该线程池中线程总数最大值
该值等于核心线程数量 + 非核心线程数量。
long keepAliveTime:非核心线程闲置超时时长
非核心线程如果处于闲置状态超过该值,就会被销毁。如果设置allowCoreThreadTimeOut(true),则会也作用于核心线程。
TimeUnit unit:keepAliveTime的单位
TimeUnit是一个枚举类型 ,包括以下属性:
NANOSECONDS : 1微毫秒 = 1微秒 / 1000
MICROSECONDS : 1微秒 = 1毫秒 / 1000 MILLISECONDS : 1毫秒 = 1秒 /1000 SECONDS : 秒 MINUTES : 分 HOURS : 小时 DAYS : 天BlockingQueue workQueue: 阻塞队列,维护着等待执行的 Runnable 任务对象
1
2
3
4
5
6
7
8
9
10
11
12
13常用的几个阻塞队列:
- LinkedBlockingQueue
链式阻塞队列,底层数据结构是链表,默认大小是Integer.MAX_VALUE,也可以指定大小。
- ArrayBlockingQueue
数组阻塞队列,底层数据结构是数组,需要指定队列的大小。
- SynchronousQueue
同步队列,内部容量为0,每个put操作必须等待一个take操作,反之亦然。
- DelayQueue
延迟队列,该队列中的元素只有当其指定的延迟时间到了,才能够从队列中获取到该元素
还有两个非必须的参数:
ThreadFactory threadFactory :
创建线程的工厂 ,用于批量创建线程,统一在创建线程时设置一些参数,如是否守护线程、线程的优先级等。如果不指定,会新建一个默认的线程工厂。1
2
3
4
5
6
7
8
9
10
11
12
13
14static class DefaultThreadFactory implements ThreadFactory {
// 省略属性
// 构造函数
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "pool-" +
poolNumber.getAndIncrement() +
"-thread-";
}
// 省略
}RejectedExecutionHandler handler:饱和策略
拒绝处理策略,线程数量大于最大线程数就会采用拒绝处理策略,四种拒绝处理的策略为 :1
2
3
4
5
6
7- ThreadPoolExecutor.AbortPolicy:默认拒绝处理策略,丢弃任务并抛出RejectedExecutionException异常。
- ThreadPoolExecutor.DiscardPolicy:丢弃新来的任务,但是不抛出异常。
- ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列头部(最旧的)的任务,然后重新尝试执行程序(如果再次失败,重复此过程)。
- ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务。当我们不指定 RejectedExecutionHandler 饱和策略的话来配置线程池的时候默认使用的是 ThreadPoolExecutor.AbortPolicy。在默认情况下,ThreadPoolExecutor 将抛出 RejectedExecutionException 来拒绝新来的任务 ,这代表你将丢失对这个任务的处理。 对于可伸缩的应用程序,建议使用 ThreadPoolExecutor.CallerRunsPolicy。当最大池被填满时,此策略为我们提供可伸缩队列。
一个简单的线程池 Demo
代码如下:
1 | public class ThreadPoolExecutorDemo { |
输出结果:
线程池原理分析
处理任务的核心方法是execute,我们看看 JDK 1.8 源码中ThreadPoolExecutor是如何处理线程任务的:
1 | // 存放线程池的运行状态 (runState) 和线程池内有效线程的数量 (workerCount) |
ThreadPoolExecutor execute的整个处理过程如下图所示: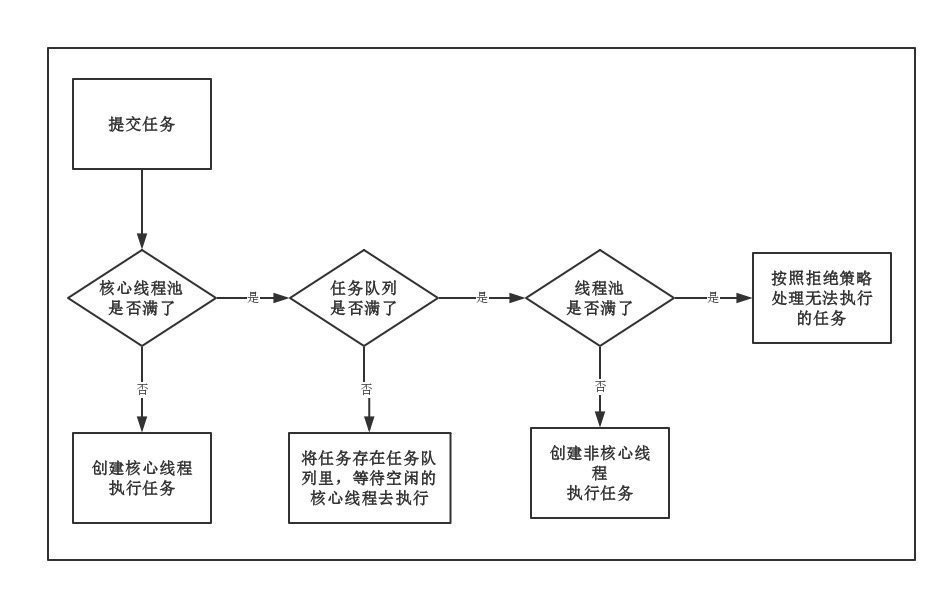
总结一下处理流程有下面几个步骤:
线程总数量 < corePoolSize,无论线程是否空闲,都会新建一个核心线程执行任务(让核心线程数量快速达到corePoolSize,在核心线程数量 < corePoolSize时)。注意,这一步需要获得全局锁。
线程总数量 >= corePoolSize时,新来的线程任务会进入任务队列中等待,然后空闲的核心线程会依次去缓存队列中取任务来执行(体现了线程复用)。
当缓存队列满了,说明这个时候任务已经多到爆棚,需要一些“临时工”来执行这些任务了。于是会创建非核心线程去执行这个任务。注意,这一步需要获得全局锁。
缓存队列满了, 且总线程数达到了maximumPoolSize,则会采取上面提到的拒绝策略进行处理。
参考文章
1.《并发编程的艺术》
2. 线程池原理
3. java线程池实现原理与源码分析(jdk1.8)
4. Java线程池实现原理及其在美团业务中的实践
5. 聊聊并发(三)——JAVA线程池的分析和使用