实战一(上):业务开发常用的基于贫血模型的MVC架构违背OOP吗?
1.什么是基于贫血模型的传统开发模式?
像下面 UserBo 这样,只包含数据,不包含业务逻辑的类,就叫作贫血模型(Anemic Domain Model)。同理,UserEntity、UserVo 都是基于贫血模型设计的。这种贫血模型将数据与操作分离,破坏了面向对象的封装特性,是一种典型的面向过程的编程风格。
1 |
|
2.什么是基于充血模型的 DDD 开发模式?
在贫血模型中,数据和业务逻辑被分割到不同的类中。充血模型(Rich Domain Model)正好相反,数据和对应的业务逻辑被封装到同一个类中。因此,这种充血模型满足面向对象的封装特性,是典型的面向对象编程风格。
3.贫血模型 与 充血模型的代码模式区别
基于贫血模型的传统开发模式中,Service 层包含 Service 类和 BO 类两部分,BO 是贫血模型,只包含数据,不包含具体的业务逻辑。业务逻辑集中在 Service 类中。在基于充血模型的 DDD 开发模式中,Service 层包含 Service 类和 Domain 类两部分。Domain 就相当于贫血模型中的 BO。不过,Domain 与 BO 的区别在于它是基于充血模型开发的,既包含数据,也包含业务逻辑。而 Service 类变得非常单薄。总结一下的话就是,基于贫血模型的传统的开发模式,重 Service 轻 BO;基于充血模型的 DDD 开发模式,轻 Service 重 Domain。
4.为什么基于贫血模型的传统开发模式如此受欢迎?
一点原因是,大部分情况下,我们开发的系统业务可能都比较简单,简单到就是基于 SQL 的 CRUD 操作,基于贫血模型的传统开发模式简单够用
第二点原因是,充血模型的设计要比贫血模型更加有难度。因为充血模型是一种面向对象的编程风格。我们从一开始就要设计好针对数据要暴露哪些操作,定义哪些业务逻辑。而不是像贫血模型那样,我们只需要定义数据,之后有什么功能开发需求,我们就在 Service 层定义什么操作,不需要事先做太多设计。
思维已固化,转型有成本
5.什么时候该选择用贫血模型?什么时候该用充血模型?
基于贫血模型的传统开发模式,是典型的面向过程的编程风格。相反,基于充血模型的 DDD 开发模式,是典型的面向对象的编程风格。
对于业务不复杂的系统开发来说,基于贫血模型的传统开发模式简单够用,基于充血模型的 DDD 开发模式有点大材小用,无法发挥作用。相反,对于业务复杂的系统开发来说,基于充血模型的 DDD 开发模式,因为前期需要在设计上投入更多时间和精力,来提高代码的复用性和可维护性,所以相比基于贫血模型的开发模式,更加有优势。
实战一(下):如何利用基于充血模型的DDD开发一个虚拟钱包系统?
钱包系统的设计思路
很多具有支付、购买功能的应用(比如淘宝、滴滴出行、极客时间等)都支持钱包的功能。应用为每个用户开设一个系统内的虚拟钱包账户,支持用户充值、提现、支付、冻结、透支、转赠、查询账户余额、查询交易流水等操作。下图是一张典型的钱包功能界面,你可以直观地感受一下。
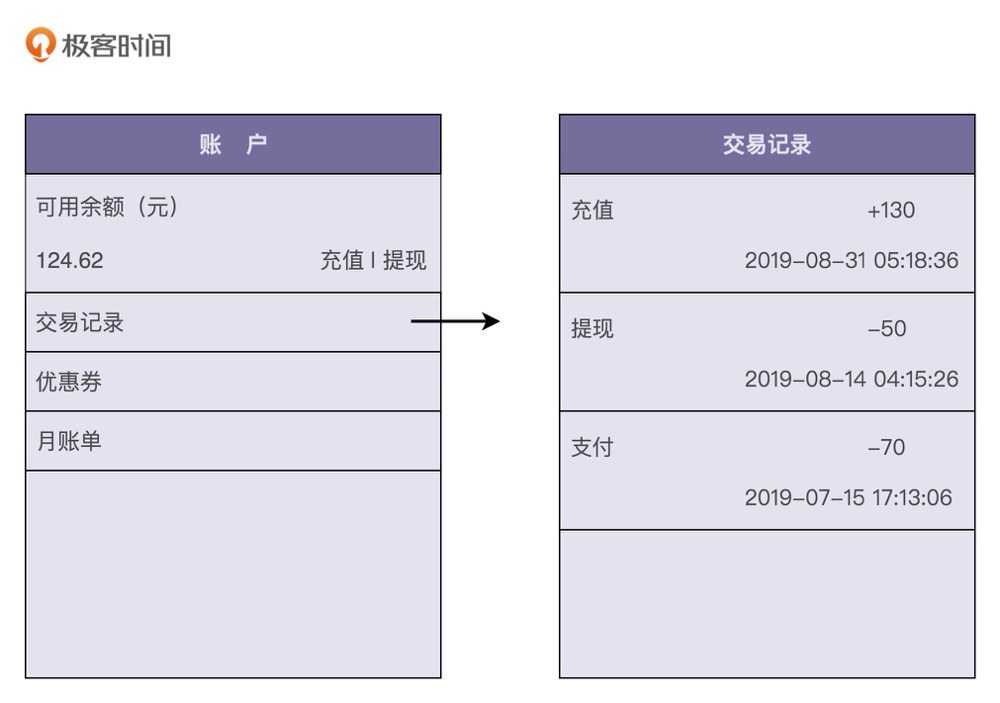
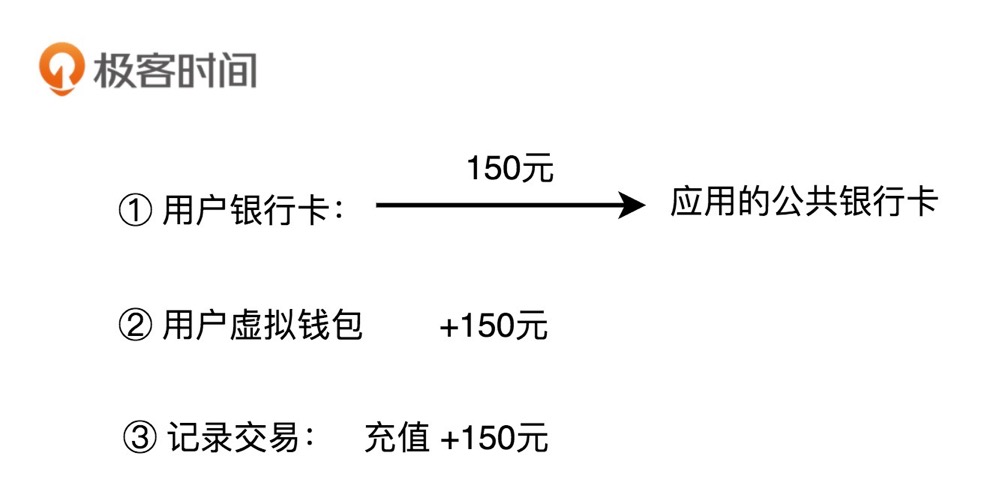
1.充值
充值用户通过三方支付渠道,把自己银行卡账户内的钱,充值到虚拟钱包账号中。这整个过程,我们可以分解为三个主要的操作流程:第一个操作是从用户的银行卡账户转账到应用的公共银行卡账户;第二个操作是将用户的充值金额加到虚拟钱包余额上;第三个操作是记录刚刚这笔交易流水
2. 支付
用户用钱包内的余额,支付购买应用内的商品。实际上,支付的过程就是一个转账的过程,从用户的虚拟钱包账户划钱到商家的虚拟钱包账户上。除此之外,我们也需要记录这笔支付的交易流水信息。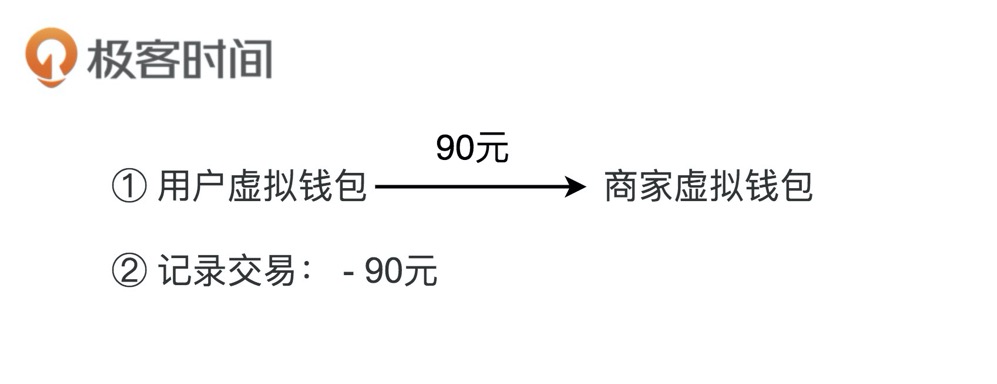
3. 提现
除了充值、支付之外,用户还可以将虚拟钱包中的余额,提现到自己的银行卡中。这个过程实际上就是扣减用户虚拟钱包中的余额,并且触发真正的银行转账操作,从应用的公共银行账户转钱到用户的银行账户。同样,我们也需要记录这笔提现的交易流水信息。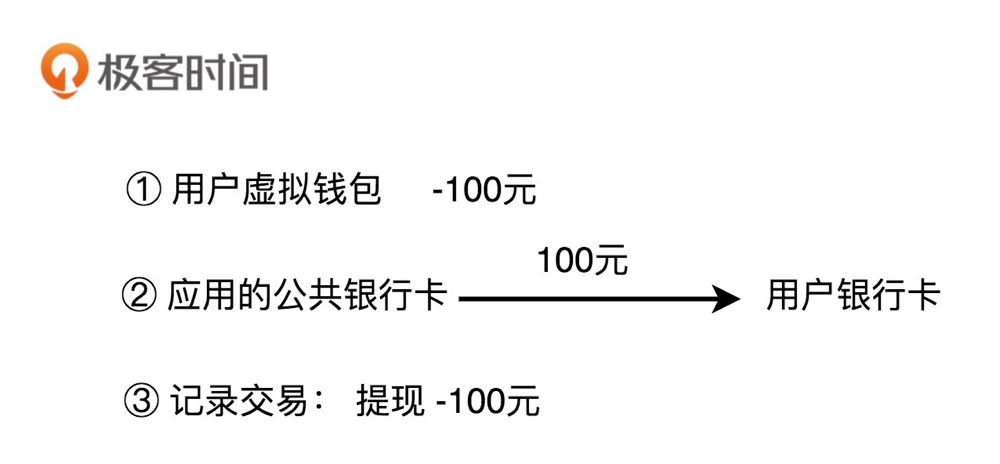
4.查询余额
查询余额功能比较简单,我们看一下虚拟钱包中的余额数字即可。
5.查询交易流水
查询交易流水也比较简单。我们只支持三种类型的交易流水:充值、支付、提现。在用户充值、支付、提现的时候,我们会记录相应的交易信息。在需要查询的时候,我们只需要将之前记录的交易流水,按照时间、类型等条件过滤之后,显示出来即可。
钱包系统的设计思路
可以把整个钱包系统的业务划分为两部分,其中一部分单纯跟应用内的虚拟钱包账户打交道,另一部分单纯跟银行账户打交道。我们基于这样一个业务划分,给系统解耦,将整个钱包系统拆分为两个子系统:虚拟钱包系统和三方支付系统。
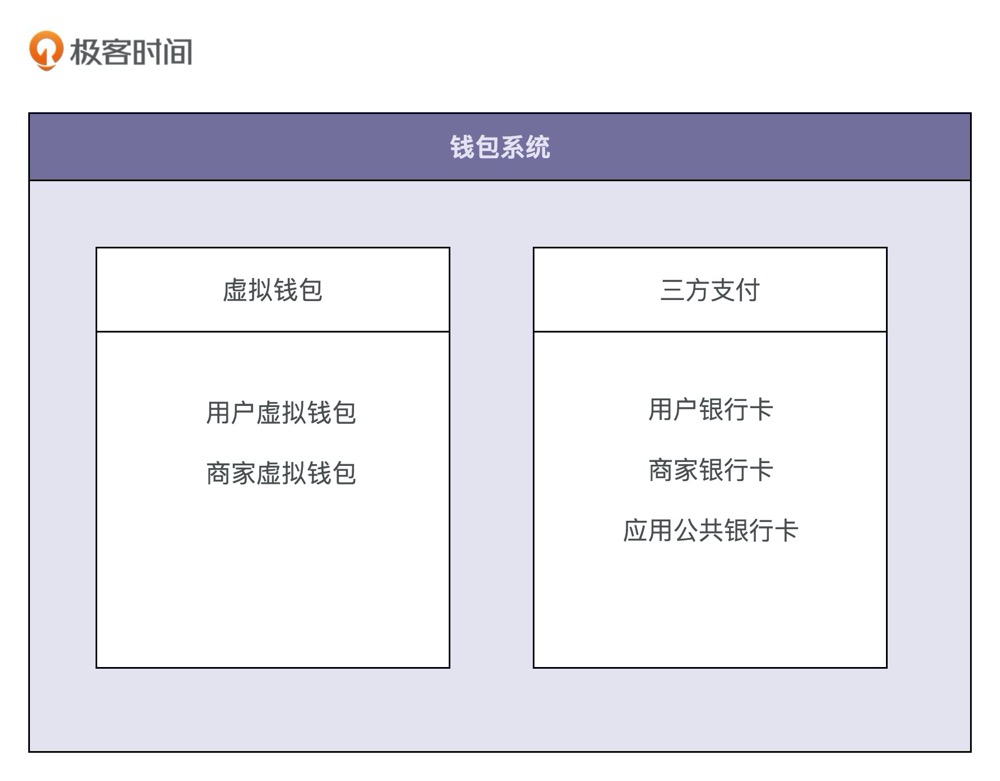
以虚拟钱包的设计为例,如果要支持钱包的这五个核心功能,虚拟钱包系统需要对应实现哪些操作。
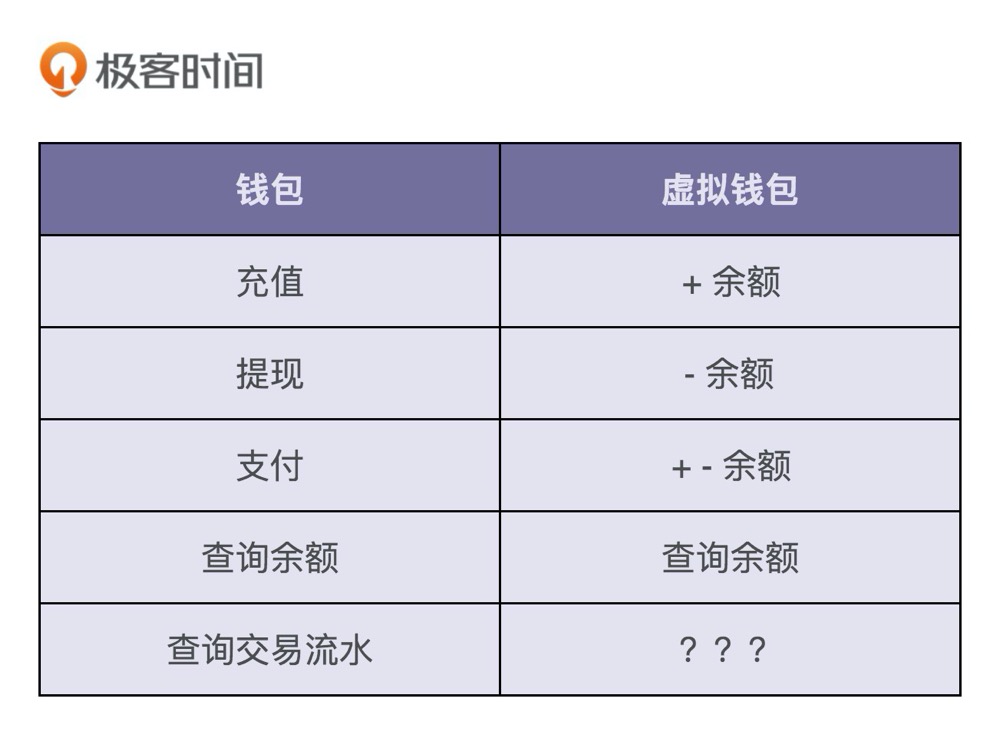
充值、提现、支付这些业务交易类型,是否应该让虚拟钱包系统感知?
虚拟钱包系统不应该感知具体的业务交易类型。我们前面讲到,虚拟钱包支持的操作,仅仅是余额的加加减减操作,不涉及复杂业务概念,职责单一、功能通用。如果耦合太多业务概念到里面,势必影响系统的通用性,而且还会导致系统越做越复杂。因此,我们不希望将充值、支付、提现这样的业务概念添加到虚拟钱包系统中。
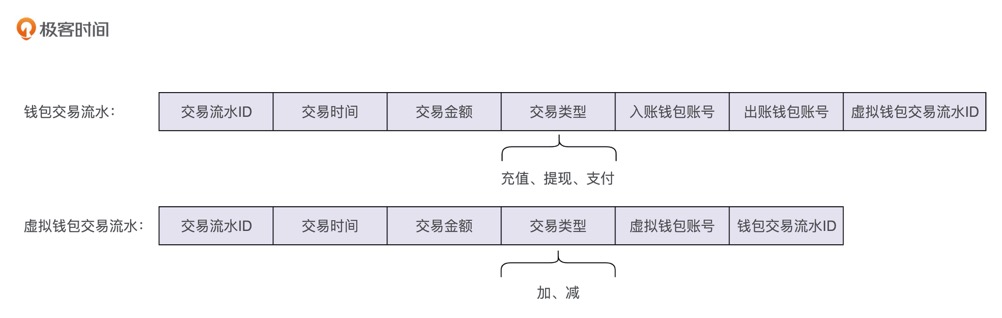
如果我们不在虚拟钱包系统的交易流水中记录交易类型,那在用户查询交易流水的时候,如何显示每条交易流水的交易类型呢?
可以通过记录两条交易流水信息的方式来解决。我们前面讲到,整个钱包系统分为两个子系统,上层钱包系统的实现,依赖底层虚拟钱包系统和三方支付系统。对于钱包系统来说,它可以感知充值、支付、提现等业务概念,所以,我们在钱包系统这一层额外再记录一条包含交易类型的交易流水信息,而在底层的虚拟钱包系统中记录不包含交易类型的交易流水信息。
基于贫血模型的传统开发模式
是一个典型的 Web 后端项目的三层结构。其中,Controller 和 VO 负责暴露接口,具体的代码实现如下所示。注意,Controller 中,接口实现比较简单,主要就是调用 Service 的方法,所以,省略了具体的代码实现。
1 | public class VirtualWalletController { |
Service 和 BO 负责核心业务逻辑,Repository 和 Entity 负责数据存取。
1 |
|
基于充血模型的 DDD 开发模式
跟基于贫血模型的传统开发模式的主要区别就在 Service 层,Controller 层和 Repository 层的代码基本上相同。所以,我们重点看一下,Service 层按照基于充血模型的 DDD 开发模式该如何来实现。
把虚拟钱包 VirtualWallet 类设计成一个充血的 Domain 领域模型,并且将原来在 Service 类中的部分业务逻辑移动到 VirtualWallet 类中,让 Service 类的实现依赖 VirtualWallet 类。
1 |
|
小结
基于充血模型的 DDD 开发模式跟基于贫血模型的传统开发模式相比,主要区别在 Service 层。在基于充血模型的开发模式下,我们将部分原来在 Service 类中的业务逻辑移动到了一个充血的 Domain 领域模型中,让 Service 类的实现依赖这个 Domain 类。
在基于充血模型的 DDD 开发模式下,Service 类并不会完全移除,而是负责一些不适合放在 Domain 类中的功能。比如,负责与 Repository 层打交道、跨领域模型的业务聚合功能、幂等事务等非功能性的工作。
基于充血模型的 DDD 开发模式跟基于贫血模型的传统开发模式相比,Controller 层和 Repository 层的代码基本上相同。这是因为,Repository 层的 Entity 生命周期有限,Controller 层的 VO 只是单纯作为一种 DTO。两部分的业务逻辑都不会太复杂。业务逻辑主要集中在 Service 层。所以,Repository 层和 Controller 层继续沿用贫血模型的设计思路是没有问题的。
精彩评论:充血模型可以说是业务的精准抽象
我对DDD的看法就是,它可以把原来最重的service逻辑拆分并且转移一部分逻辑,可以使得代码可读性略微提高,另一个比较重要的点是使得模型充血以后,基于模型的业务抽象在不断的迭代之后会越来越明确,业务的细节会越来越精准,通过阅读模型的充血行为代码,能够极快的了解系统的业务,对于开发来说能说明显的提升开发效率。
在维护性上来说,如果项目新进了开发人员,如果是贫血模型的service代码,无论代码如何清晰,注释如何完备,代码结构设计得如何优雅,都没有办法第一时间理解系统的核心业务逻辑,但是如果是充血模型,直接阅读充血模型的行为方法,起码能够很快理解70%左右的业务逻辑,因为充血模型可以说是业务的精准抽象,我想,这就是领域模型驱动能够达到”驱动”效果的由来吧。
实战二(上):如何对接口鉴权这样一个功能开发做面向对象分析?
需求:
为了保证接口调用的安全性,我们希望设计实现一个接口调用鉴权功能,只有经过认证之后的系统才能调用我们的接口,没有认证过的系统调用我们的接口会被拒绝。
分析:
1.第一轮寄出分析:
对于如何做鉴权这样一个问题,最简单的解决方案就是,通过用户名加密码来做认证。我们给每个允许访问我们服务的调用方,派发一个应用名(或者叫应用 ID、AppID)和一个对应的密码(或者叫秘钥)。调用方每次进行接口请求的时候,都携带自己的 AppID 和密码。微服务在接收到接口调用请求之后,会解析出 AppID 和密码,跟存储在微服务端的 AppID 和密码进行比对。如果一致,说明认证成功,则允许接口调用请求;否则,就拒绝接口调用请求。
2.第二轮优化分析
不过,这样的验证方式,每次都要明文传输密码。密码很容易被截获,是不安全的, 存在 重放攻击问题。我们可以借助 OAuth 的验证思路来解决。调用方将请求接口的 URL 跟 AppID、密码拼接在一起,然后进行加密,生成一个 token。调用方在进行接口请求的的时候,将这个 token 及 AppID,随 URL 一块传递给微服务端。微服务端接收到这些数据之后,根据 AppID 从数据库中取出对应的密码,并通过同样的 token 生成算法,生成另外一个 token。用这个新生成的 token 跟调用方传递过来的 token 对比。如果一致,则允许接口调用请求;否则,就拒绝接口调用请求。
3.第三轮优化分析
4.第四轮优化分析

调用方进行接口请求的时候,将 URL、AppID、密码、时间戳拼接在一起,通过加密算法生成 token,并且将 token、AppID、时间戳拼接在 URL 中,一并发送到微服务端。微服务端在接收到调用方的接口请求之后,从请求中拆解出 token、AppID、时间戳。微服务端首先检查传递过来的时间戳跟当前时间,是否在 token 失效时间窗口内。如果已经超过失效时间,那就算接口调用鉴权失败,拒绝接口调用请求。如果 token 验证没有过期失效,微服务端再从自己的存储中,取出 AppID 对应的密码,通过同样的 token 生成算法,生成另外一个 token,与调用方传递过来的 token 进行匹配;如果一致,则鉴权成功,允许接口调用,否则就拒绝接口调用。
小结
开发像鉴权这样的非业务功能,最好不要与具体的第三方系统有过度的耦合。针对 AppID 和密码的存储,我们最好能灵活地支持各种不同的存储方式,比如 ZooKeeper、本地配置文件、自研配置中心、MySQL、Redis 等。我们不一定针对每种存储方式都去做代码实现,但起码要留有扩展点,保证系统有足够的灵活性和扩展性,能够在我们切换存储方式的时候,尽可能地减少代码的改动。
针对框架、类库、组件等非业务系统的开发,其中一个比较大的难点就是,需求一般都比较抽象、模糊,需要你自己去挖掘,做合理取舍、权衡、假设,把抽象的问题具象化,最终产生清晰的、可落地的需求定义。需求定义是否清晰、合理,直接影响了后续的设计、编码实现是否顺畅。所以,作为程序员,你一定不要只关心设计与实现,前期的需求分析同等重要。
需求分析的过程实际上是一个不断迭代优化的过程。我们不要试图一下就能给出一个完美的解决方案,而是先给出一个粗糙的、基础的方案,有一个迭代的基础,然后再慢慢优化,这样一个思考过程能让我们摆脱无从下手的窘境。
3.针对框架、组件、类库等非业务系统的开发,我们一定要有组件化意识、框架意识、抽象意识,开发出来的东西要足够通用,不能局限于单一的某个业务需求
精彩评论
1.工作中遇到非crud的需求我就会想尽一切办法让他通用,基本需求分析和需求设计的时间占用百分之五十,开发和重构到自认为最优占用百分之五十。比如最简单的验证码功能,几乎每个项目都有,我就封装一套验证码服务,主要功能有你在配置文件里配置好需要被验证码拦截的路径,这里还要考虑到通配符,空格等等细节和可扩展的点,内置图片验证码,极验证,手机验证以及自定义验证码等等,总之我认为如果有机会遇到非crud的需求,一定要好好珍惜,好好把握,把他打造成属于自己的产品,这样会让自己下意识的去想尽一切办法把他做到最优,亲儿子一样的待遇,再也不会无脑cv
- 一句话:使用进化算法的思想,提出一个MVP(最小可行性产品),逐步迭代改进。
拿到这个需求,假设我们不了解接口鉴权,需求又不明确,我会我自己如下问题: - 什么叫接口鉴权?搞清基本概念
- 接口鉴权最佳实践是什么?技术调研
- appid和secret key从哪里来?用户自己申请还是我们授权?用户申请是以什么方式申请(网页还是邮件?申请的网页有人做了么?)追问下去。
- appid secretkey存储在什么地方呢?数据存储
- 用户如何使用?需要为用户提供接口鉴权使用手册和文档,及示例代码。写用户手册,文档。
- 这个功能如何测试?提前想好如何测试
- 接口鉴权功能何时上线?估计工期
- 鉴权成功或失败返回码和信息定义?约定返回结果
关于防止重放攻击:请求参数中还可以加入nonce(随机正整数),两次请求的nonce不能重复,timestamp和nonce结合进一步防止重放攻击。
- 程序员十倍法则
实战二(下):如何利用面向对象设计和编程开发接口鉴权功能?
向对象分析的产出是详细的需求描述。面向对象设计的产出是类。在面向对象设计这一环节中,我们将需求描述转化为具体的类的设计。这个环节的工作可以拆分为下面四个部分。
1. 划分职责进而识别出有哪些类
根据需求描述,我们把其中涉及的功能点,一个一个罗列出来,然后再去看哪些功能点职责相近,操作同样的属性,可否归为同一个类。
例子:我们要做的是逐句阅读上面的需求描述,拆解成小的功能点,一条一条罗列下来。注意,拆解出来的每个功能点要尽可能的小。每个功能点只负责做一件很小的事情(专业叫法是“单一职责”,后面章节中我们会讲到)。下面是我逐句拆解上述需求描述之后,得到的功能点列表:
1.把 URL、AppID、密码、时间戳拼接为一个字符串;
2.对字符串通过加密算法加密生成 token;
3.将 token、AppID、时间戳拼接到 URL 中,形成新的 URL;
4.解析 URL,得到 token、AppID、时间戳等信息;
5.从存储中取出 AppID 和对应的密码;
6.根据时间戳判断 token 是否过期失效;
7.验证两个 token 是否匹配;
从上面的功能列表中,我们发现,1、2、6、7 都是跟 token 有关,负责 token 的生成、验证;3、4 都是在处理 URL,负责 URL 的拼接、解析;5 是操作 AppID 和密码,负责从存储中读取 AppID 和密码。所以,我们可以粗略地得到三个核心的类:AuthToken、Url、CredentialStorage。AuthToken 负责实现 1、2、6、7 这四个操作;Url 负责 3、4 两个操作;CredentialStorage 负责 5 这个操作。
2. 定义类及其属性和方法
我们识别出需求描述中的动词,作为候选的方法,再进一步过滤筛选出真正的方法,把功能点中涉及的名词,作为候选属性,然后同样再进行过滤筛选。
刚刚我们通过分析需求描述,识别出了三个核心的类,它们分别是 AuthToken、Url 和 CredentialStorage
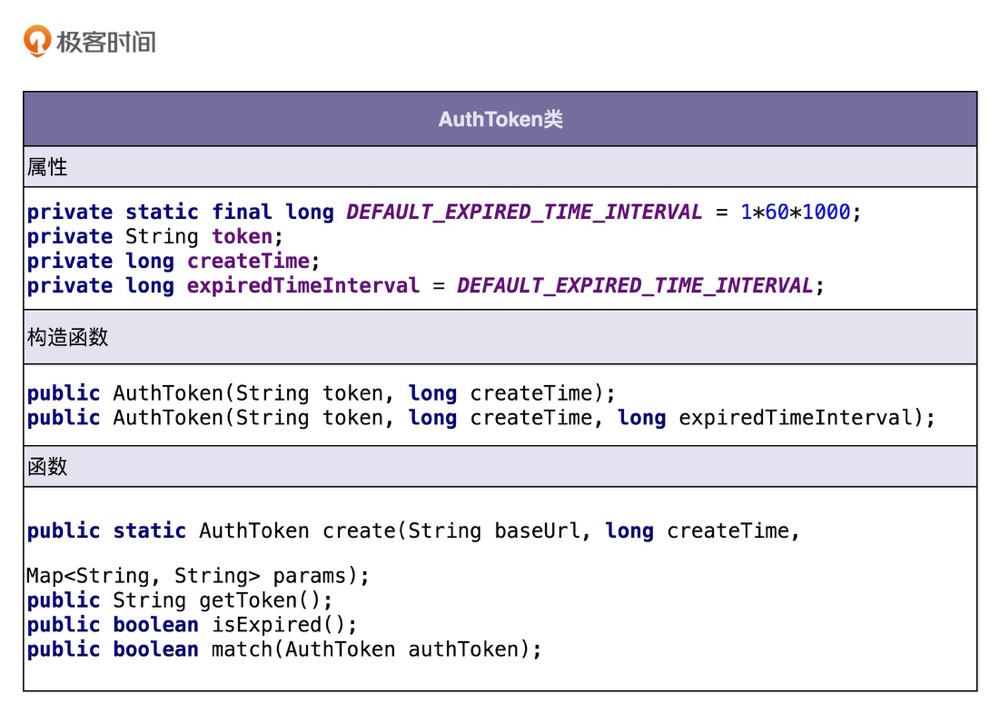
AuthToken 类相关的功能点有四个:
- 把 URL、AppID、密码、时间戳拼接为一个字符串;
- 对字符串通过加密算法加密生成 token;
- 根据时间戳判断 token 是否过期失效;
- 验证两个 token 是否匹配。
Url 类相关的功能点有两个:
- 将 token、AppID、时间戳拼接到 URL 中,形成新的 URL;
- 解析 URL,得到 token、AppID、时间戳等信息。
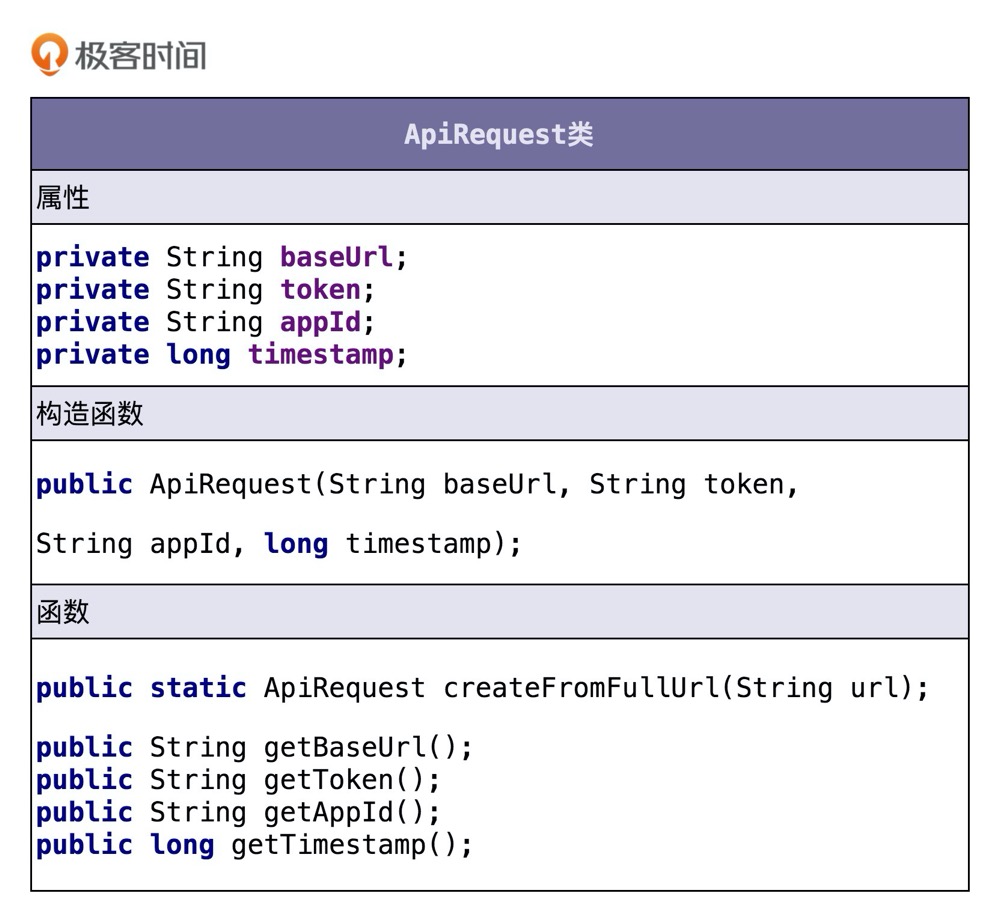
CredentialStorage 类相关的功能点有一个:
- 从存储中取出 AppID 和对应的密码。

3. 定义类与类之间的交互关系
UML 统一建模语言中定义了六种类之间的关系。它们分别是:泛化、实现、关联、聚合、组合、依赖。我们从更加贴近编程的角度,对类与类之间的关系做了调整,保留四个关系:泛化、实现、组合、依赖。
泛化(Generalization)可以简单理解为继承关系:
1 | public class A { ... } |
实现(Realization)一般是指接口和实现类之间的关系
1 | public interface A {...} |
组合 (Composition)只要 B 类对象是 A 类对象的成员变量,那我们就称,A 类跟 B 类是组合关系强调部分与整体的关系,其中包括两种情况,关联性强(大雁与翅膀)的与关联性弱(学生与班级)的。(这里将将 UML 定义的 关联、聚合、组合 统一归类为组合)
1 |
|
依赖(Dependency)是一种比关联关系更加弱的关系,包含关联关系。不管是 B 类对象是 A 类对象的成员变量,还是 A 类的方法使用 B 类对象作为参数或者返回值、局部变量,只要 B 类对象和 A 类对象有任何使用关系,我们都称它们有依赖关系。具体到 Java 代码就是下面这样:
1 |
|
4. 将类组装起来并提供执行入口
我们要将所有的类组装在一起,提供一个执行入口。这个入口可能是一个 main() 函数,也可能是一组给外部用的 API 接口。通过这个入口,我们能触发整个代码跑起来。
评论区的代码实现参考
https://github.com/gdhucoder/Algorithms4/tree/master/geekbang/designpattern/u014
https://gitee.com/MondayLiu/geek-design
https://github.com/LiuKay/design-patterns-java/tree/master/src/main/java/com/kay/practice/auth